pytesseractよりeasyocrの方がテキスト抽出できた話
画像の翻訳プログラムを作っている中で、そもそもテキストがうまく抽出できない問題が発生した。
もともと使っていたのは pytesseract 。
昔使ってたからそのままコード流用してみたが、プリセットでは期待する精度で検出ができなかった。
そんな中 easyocr なるものを見つけ試しに使ってみたら期待する抽出結果をくれた。
もちろん強強エンジニアであれば pytesseract をチューニングして使いこなすのだろうが、私は弱々エンジニアである。
簡単に使えて効果がでるものがあればそれが1番である。
検出比較
コードはこんな感じで。pytesseractのpsmは1番精度が良かったものを使用。
import cv2
import easyocr
import pytesseract
image = cv2.imread("path/to/image.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 画像をグレースケールに変換
_, image = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY) # グレースケール画像を2値化
# OCRを適用してテキストを抽出
pytesseract_text = pytesseract.image_to_string(image, lang="chi_sim", config="--psm 6")
print(f"pytesseract: {pytesseract_text}")
reader = easyocr.Reader(["ch_sim"])
easyocr_text = reader.readtext(image, detail=0)
print(f"easyocr_text: {easyocr_text}")
サンプル画像1

どうでしょう。easyocrの方は良い感じ。
pytesseract: 为H和9
easyocr_text: ['为什么.?']
サンプル画像2

pytesseractも読み取れているが、「RN 5」というノイズが混じっているのと、愉下的は趴下的が正しい。
pytesseract: RN 5
该死的,本来想直接
把他给打愉下的|
easyocr_text: ['该死的', '本来想直接', '把他给打趴下的!']
サンプル画像3
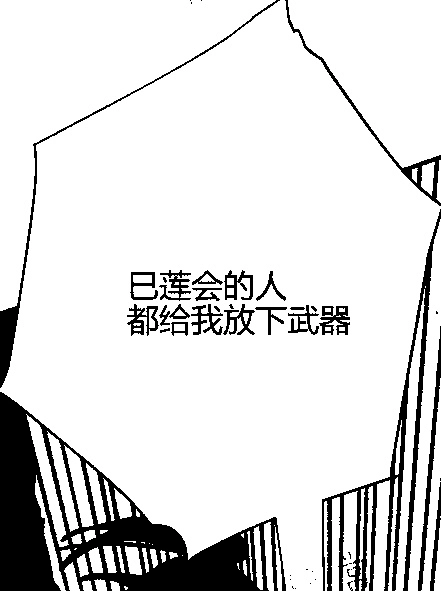
安定して読み取れています。
pytesseract: 反、
|
easyocr_text: ['巳莲会的人', '都给我放下武器']
最後に
easyocr...強力でしたね。簡単に利用できることが1番素晴らしいことだと思います。
参考
- https://github.com/JaidedAI/EasyOCR (opens new window)
- https://pypi.org/project/pytesseract/ (opens new window)
以上。